In the process of introducing an analytics application to an existing production, projects typically follow a process model for guidance and orientation. Most of the project consider a process like CRISP-DM that contains steps like business case analysis, data preparation, model building and testing. It is also very common to adopt some sort of iterative feedback process like build-measure-learn (lean startup) and others. Having set up a buiseness case and the necessary conditions in a company like budget, management commitment etc. teams typically aim for a first low hanging fruit: the good old proof of concept (PoC). This first prototype should be reached with minimum effort in time and money and demonstrate the feasibility of the initial idea.
Let’s have a look at such a PoC: It should be a cheap, fast proof of some of the important assumptions for the solution of the focusses business case. So – in many cases – it is a combination of existing tools, previous projects and some hacks to glue it all together for a first demo, to get the go from responsible managers. If all that runs well we go now into the next phase of creating a machine learning application for the productive use. At this phase, many project get stuck or don’t continue as costs explode and the long term usability is not secured, plus continuous return of invest or the operating costs are too high or hard to be determined at all.
Looking at the life-cylce of a data science application, I propose two central elements to be introduced to tackle exactly these two problems of costs and long term usability. The team you want to bring into play here is automation and self-service. Automation keeps the operational costs down by avoiding heavy engineering during the runtime and the life-cylce of the machine learning. Self-service assures that variations in the current setup or production will not stop the effectiveness of the initial system. The users or domain experts can – with self-service – modify, retrain the machine learning system in a way that is it adapted to new requirements. So automation and self-service are great tools for supporting the life-cycle of the machine learning application where changed surroundings threaten the stability of the previous learned models and assumptions.
In this context, self-service does not serve as a build tool for applications but rather a support tool for the life-cycle of an application. We discover that automation and self-service can be used in a complementary way:

if we can realize a high level of automation, there is less need of user interaction, so less self-service needed. Or seen from the other side: if a high level of automation is hard to reach for your use case, fill in the rest with self-service to keep long term availability high and costs low.
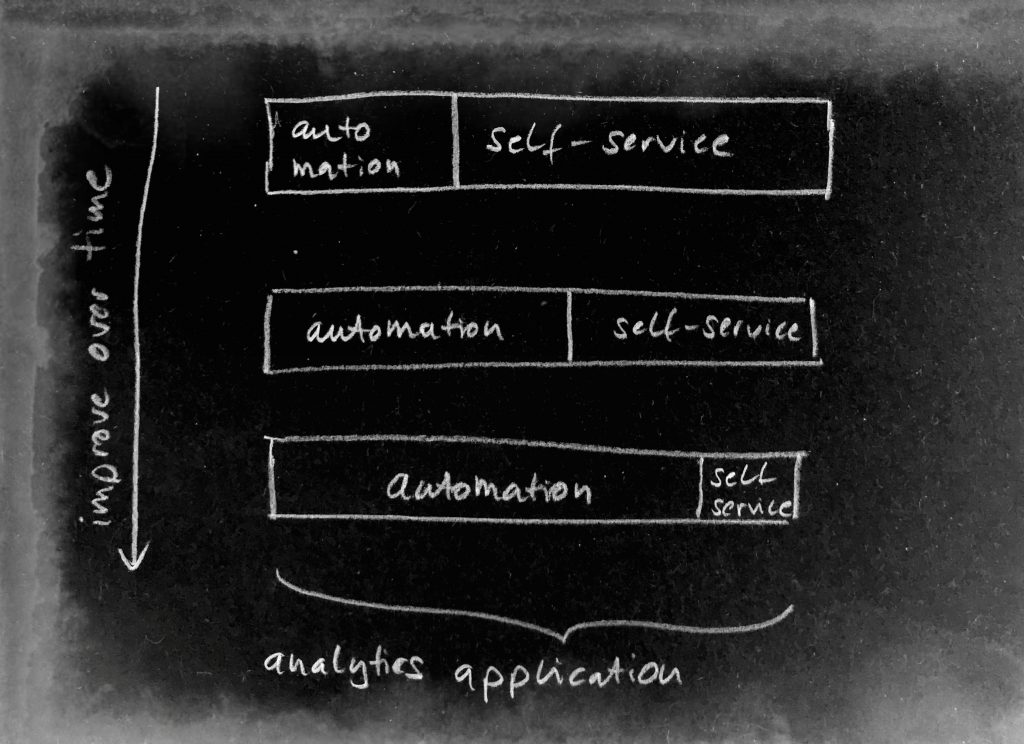
So adjusting the level of automation can be a great possibility of adjusting the cost as well: Instead of trying to figure out a robust way to set each parameter of a machine learning pipeline, we can simply present some to the user as long as we make sure we provide it in an intuitive and interactive way. I will talk about this aspect of user experience (UX) in the next blog post. So self-service can serve as a complementary part where automation is not possible due to cost or other reasons