I would like to share some thoughts on pattern search in multivariate time series data in industrial applications. The task of pattern search is highly useful for many different applications like: finding similar previous behaviour of a machine in an error case, counting process occurrencies for KPIs, early detection of anomalies.
We consider now a case where we want to search a pattern (also called motif or template in the literature) based on user annotations. For a more robust detection, we recommend that the domain expert provides multiple annotations of the pattern of interest.
Typical pattern search algorithms do not support multiple representations of the same pattern as an input to the search, so we are using these multiple annotations for preprocessing to take advantage of the available information.
The picture shows a simplified case of three variables and four user annotations of a pattern:
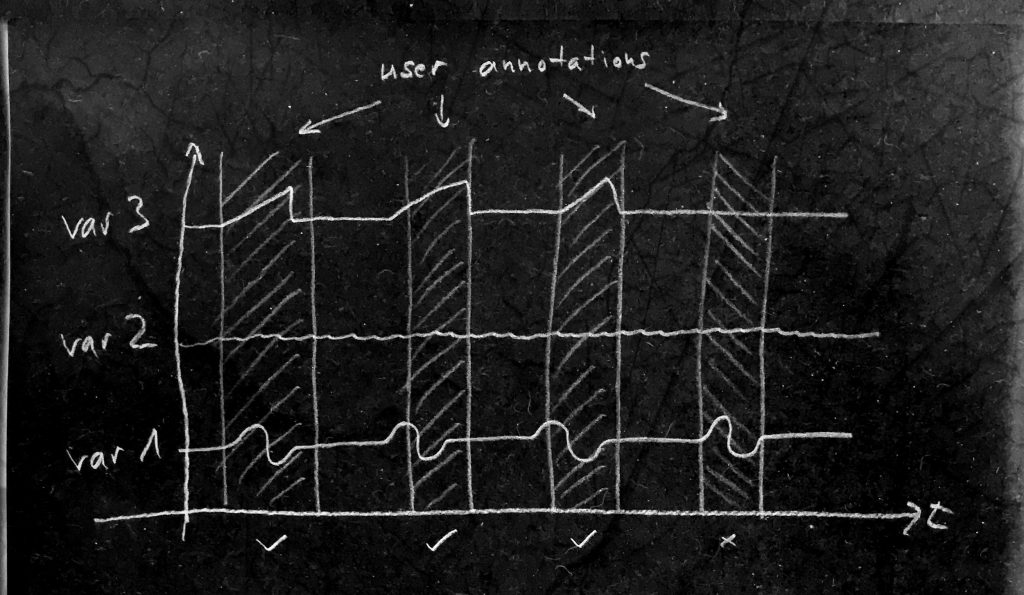
We can easily detect several weaknesses in the user annotations
- the time shifts and annotation widths are not equal and not precise
- variable 2 seams to have no relevant information for the pattern
- variable 3 shows different behaviour in the last annotation
The preprocessing steps we want to perform cover exactly these ideas. The target of this process is to select the “best” pattern as an in input to a pattern search algorithm. For this we want to
- select the useful variables
- align the pattern borders
For this we propose to use correlation as the central measure (but there are of cause other options here). We have also experienced cases where patterns on one variable look similar but other variables show a clear different behavior because the time area considered is actually not a representation of the pattern. So we introduce the idea of “negative” annotations, where the user can mark areas that look alike but are NOT the same event on the machine.
So as an input we have now: inaccurate annotations, negative annotations and all the variables as potential input to our pattern miner. With the help of cross correlation we can
- find the best alignment of the pattern by altering the borders to find a maximum
- reject misleading variables as they behave the same in positive and negative annotations
We finally select the annotation as the winner which correlates the best with all others – it represents the pattern best
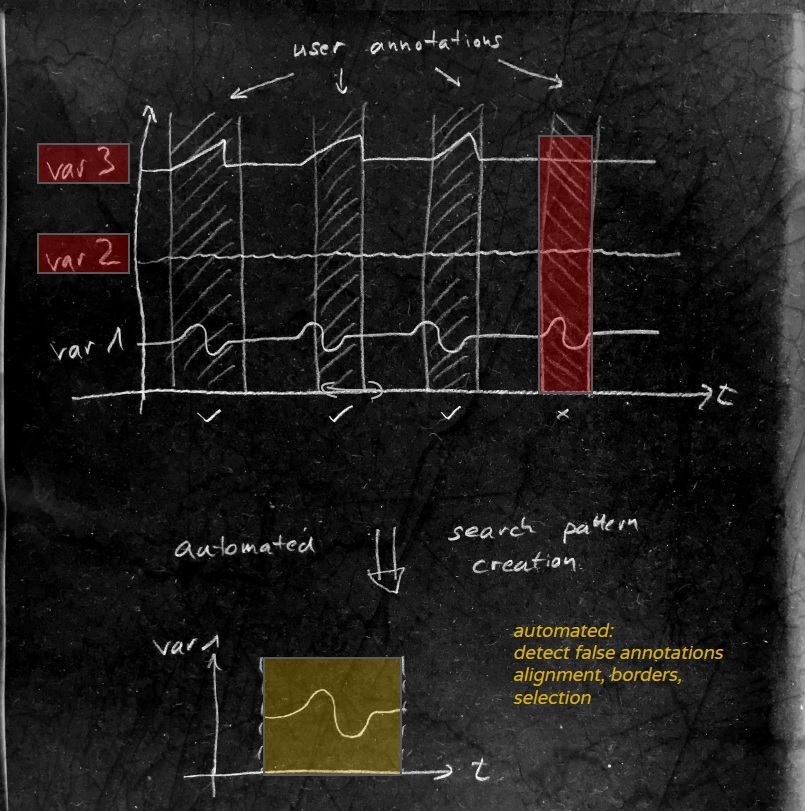
After this preprocessing, we have taken the best information of the user input and can now use all available techniques of pattern search for the actual mining like transformation, scaling, smoothing, denoising, adding noise, etc.).
Further reading and details of the algorithm can be found in our white paper Robust-Multivariate-Pattern-Mining-with-Inaccurate-User-Annotation.pdf