Most of the time when I do data science I am not working on the actual model building, but instead I work on tools and improvements to reduce my work to a minimum. I am trying to optimize my own workflow. Engineers and developers used to do that all the time: building tools to automate the work like dev-ops build scripts, automatic test cases etc. For the data science it’s a fairly new field to move the activities on a meta-level and try to optimize the way we work and reduce the interaction with supporting systems to a minimum. Before we dig deeper into this, let’s have a look on the term autonomous analytics itself. Artificial Intelligence, Machine Learning, all those terms have grown global attention, with ever increasing number of use cases in our every day life. Google search completer, Apple’s face id, deep learning and so. But what exactly is autonomous analytics? I found a few references, all of them draw a slightly different picture. On a post from modern analytics, the idea of autonomous analytics is basically to increase the number of prediction models and use them in parallel, much more than a data scientist could craft by hand. Another post in the same direction is this. The author differentiates between artisanal and autonomous analytics, where artisanal is the classical way of data crunching with a SQL data base and hand made charts to understand relationships between events. Then I found some slides from Ira Cohen, chief data scientist at anodot, they basically argue that anomaly detection using their system can include much more data, much more unknown relationsships between events and plus reduce the number of false positives (because those are finally still causing manual work). If we take this understanding to an extreme level, we want to build models that are taking many (if not all) possible relationships between inputs and outputs of a certain data science case into account and evaluate them all. We basically increase the space of features and variable interaction. There was a group founded to cover exactly this aspect, and they work with python, great! It’s the machine learning for automated algorithm design, called ml4aad. It’s about the automation of the machine learning pipeline of preprocessing, feature engineering, even model selection and evaluation. Basically the meta-level of working with machine learning. They have also shown in data challenges that they can solve problems “without any human intervention” (in their own words).
With this little research on the background I found the term still a bit fuzzy and there are still different interpretations of the meaning behind autonomous analytics. So I’ll take the chance and do my own definition and explain it in my context of work.
Autonomous analytics is the art of solving a real-world data problem with the help of machine learning while automating the whole work-flow through a system that produces the requested results with no or minimum user interaction
Let’s look at a typical work flow or processing pipeline:

We see the typical flow of activities from data ingest over data preparation, iterative modelling until we have a result. In my interpretation of an autonomous analytics system, not only the iterative modelling would be automated (just as the ml4aad-group proposes), no, the whole pipe line will be automatic, including data ingest and data prep. For each of the fields, these ideas are not new, so we find even for data preparation companies that have an optimized portfolio like trifacta and others. It sounds very attractive to have such an autonomous analytics system that covers all problems and just spits out the solution. Well, yes, but we are still not there yet! I envision that for certain cases this will be possible one day, so I propose a “lean” way of build-measure-learn towards autonomous analytics. To start with existing problems and continue generalizing through more and more use cases to finally create building blocks that work autonomously.
One case I am currently working on is a typical question arising in manufacturing, which is: We have a problem but we don’t know why it happens. So we talk about root cause analysis. Let’s look at a typical pipe line for such a data science job:
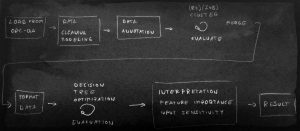
As we see, in this proposal, there are multiple steps of machine learning included. The first is part of the data preparation, the second is the actual modelling of an explanatory model. Many parts again can be automated. The clustering part covers the time segmentation, where I have shown some ideas in a previous post. But, there will always remain some interactions with the system where a user is required. The tasks will be basically two areas
- the formulation of the actual data science problem to be solved.
- giving the data a meaning
The most imprtant thing is – I believe – that the user will always be needed to give meaning. To make a clue out of correlation towards causality, to evaluate a significance, to validate a measurement. To enrich pure numbers with semantic. Humans are still (hopefully always) better in understanding the actual meaning of data, machines, works, results. Giving meaning can be as little as adding some annotation to label data for classification learners, but it can also be applying a whole data model to the raw readings with lots of relationsship between inputs (which is nowadays often called digital twin). I totally disagree with the often mentioned “big data approach”, where tons of raw data is crunched to produce the magic 42. Without meaning data is just noise.
And 1.) is also needed. Without giving focus on what to look for, an advanced autonomous analytics system could still generate a whole lot of insights, but it will very quickly overload the user’s capability of interprepation of all those results. It is something totally different if we look for outliers of a sensors reading or try to predict a machine failure two days in advance.
I see autonomous analytics as the greatest chance to create value with data science on (industrial) data. That is why I am so enthusiastic about it. I believe we are not far away from it – we have machine learning available as open source for everyone on the planet, including even the latest state of the art in deep learning. We need to carefully craft those processing pipelines and try to automate each and every parameter in the chain of processes.
Cool website!
Like the way you explain your ideas using “black boards”.
Peter
Autonomous capability, driven by machine learning, is a promising enabler of greater productivity and innovation.
value when these models automatically learn from transactions and update predictive results in real time. Not only does this reduce administration overhead, but it also eliminates human bias. This allows real-time learning to be immediately available for the next prediction, for example, to drive adaptive, high-value interactions with customers, to determine the best profile for employee candidates, or to recommend when to service critical machinery and capital assets. For business professionals, Autonomous Analytics can provide insight to inform every decision, when and where it matters, and in context. For IT, automated insights result in lower cost and enable business users to be more self-sufficient, lowering the support burden.